✅ RAG Checker
Overview
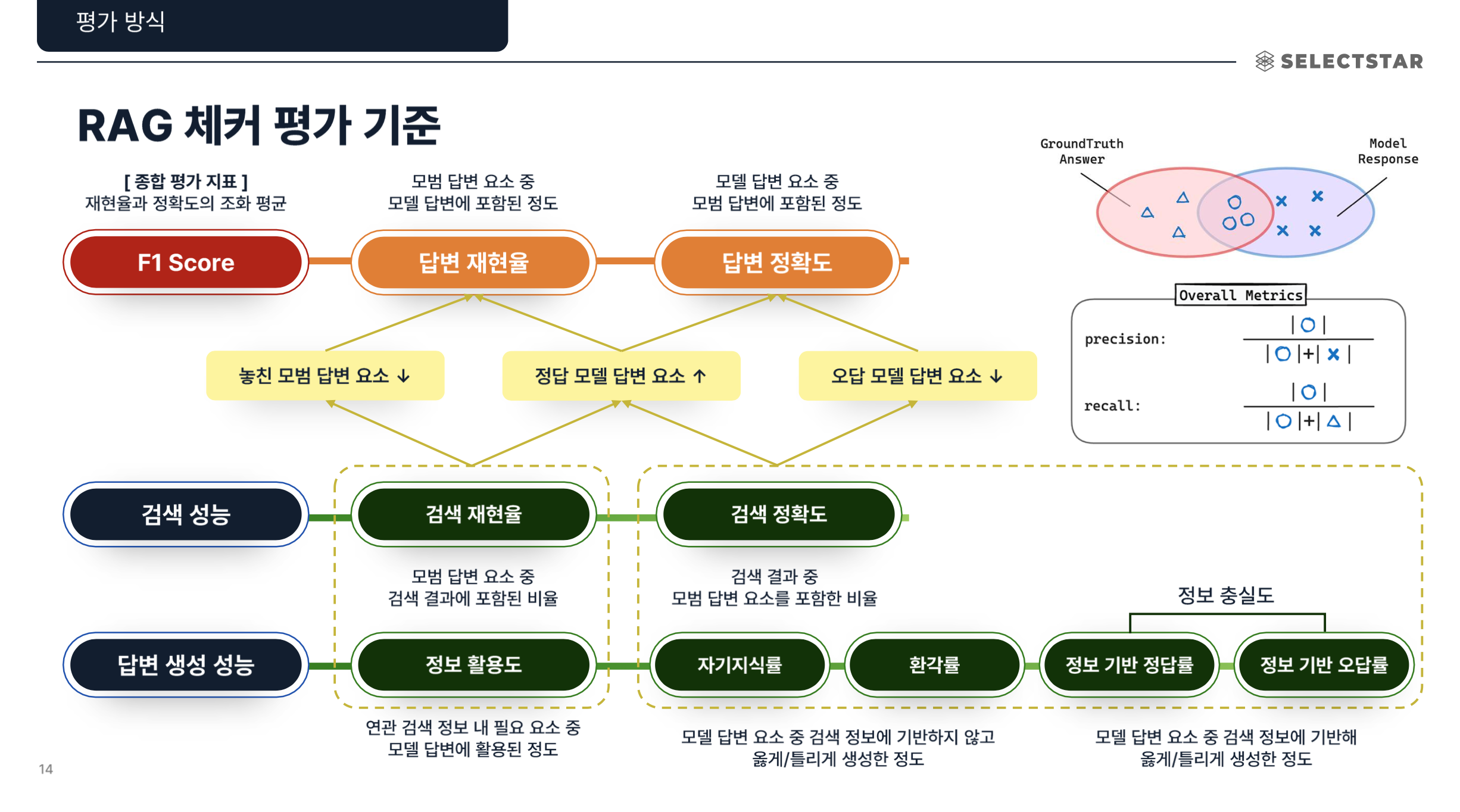
RAG 평가 시스템은 ER(Expected Response)을 기준으로 답변을 검증 가능한 단위(Claim) 로 분해하고,
각 Claim이 검색된 문맥(Passage) 으로부터 논리적으로 수반(Entailment)되는지를 판단하여
RAG 시스템의 정확성(Factuality) 과 성능 진단(Generator / Retriever 성능) 을 정량적으로 평가합니다.
시스템 구성:
내부적으로는 (1) Claim Decomposition 모듈, (2) Entailment Judge 모듈, (3) Metric Aggregator로 구성되어,
RAG의 검색(Retrieval)과 생성(Generation) 단계 성능을 각각 분리해 진단할 수 있습니다.
Flow (3-step)
-
Decomposition:
- ER(기대 응답)과 모델의 실제 응답을 Claim 단위로 분리합니다.
- 각 Claim은 “검증 가능한 사실 단위(객관적으로 참/거짓 판단 가능한 문장)”로 정의됩니다.
-
Entailment Judgment:
- 분리된 Claim이 검색된 문맥(Chunk) 으로부터 논리적으로 수반(Entailment)되는지를 LLM Judge가 판별합니다.
-
Metric Aggregation:
- Entailment 결과를 기반으로 Overall / Retriever / Generator Metrics를 계산합니다.
- 각 지표는 모델의 정확성, 충실성, 헛소리(Hallucination) 비율, 컨텍스트 활용도 등을 수치로 나타냅니다.
Metrics
Glossary
| 용어 | 정의 |
|---|---|
| ER (Expected Response) | 평가용 질문에 대해 기대되는 정답 문장(=Ground Truth Answer). |
| Claim | 검증 가능한 사실 단위. LLM을 통해 ER과 응답을 Claim 수준으로 분해(Decomposition)하여 평가에 활용. |
| Entailment | Claim이 문맥(Passage/Chunk)으로부터 논리적으로 수반되는 관계. |
| Chunk / Passage | RAG의 검색 결과로 사용되는 문서 단위(문맥). |
| Faithfulness | 모델 응답이 실제 검색 문맥에 기반했는지를 평가하는 지표. |
| Hallucination | 문맥에 기반하지 않은 잘못된 정보를 생성한 경우. |
| Noise Sensitivity | 문맥에 불필요한 정보가 있을 때 모델이 그에 영향을 받아 오답을 생성하는 정도. |
| Self-Knowledge | 검색 문맥이 없어도 모델 자체 지식으로 정답을 맞힌 경우. |
Strengths & Limitations
강점
- 세분화된 metric 구조를 통해 RAG 시스템의 Retriever / Generator 단계별 진단이 가능함.
- 정성 평가 대비, Claim 단위 기반 정량 평가로 신뢰도와 재현성 확보.
한계
- 평가 품질이 Claim Decomposition의 정확도에 의존함.
- Claim 중요도(핵심/부가 정보)를 구분하지 않기 때문에, Recall/Precision 해석 시 주의 필요
📄️ Overview
Datumo Eval evaluates RAG systems based on claim-level factuality using ER decomposition and entailment-based verification.
📄️ Run RAG Checker
RAG Checker를 어떻게 실행하나요?
📄️ View Report
평가 결과를 어떻게 해석하고 내보내나요?