Reference-based
Overview
Reference-based Evaluation은 BLEU, TER, METEOR, ROUGE, BERTScore 등의 표준 NLP 메트릭을 활용하여
모델의 출력이 **정답(Reference)**과 얼마나 유사한지를 정량적으로 평가하는 기능입니다.
Datumo Eval은 이러한 메트릭을 기반으로 LLM의 생성 품질을 자동 계산하고,
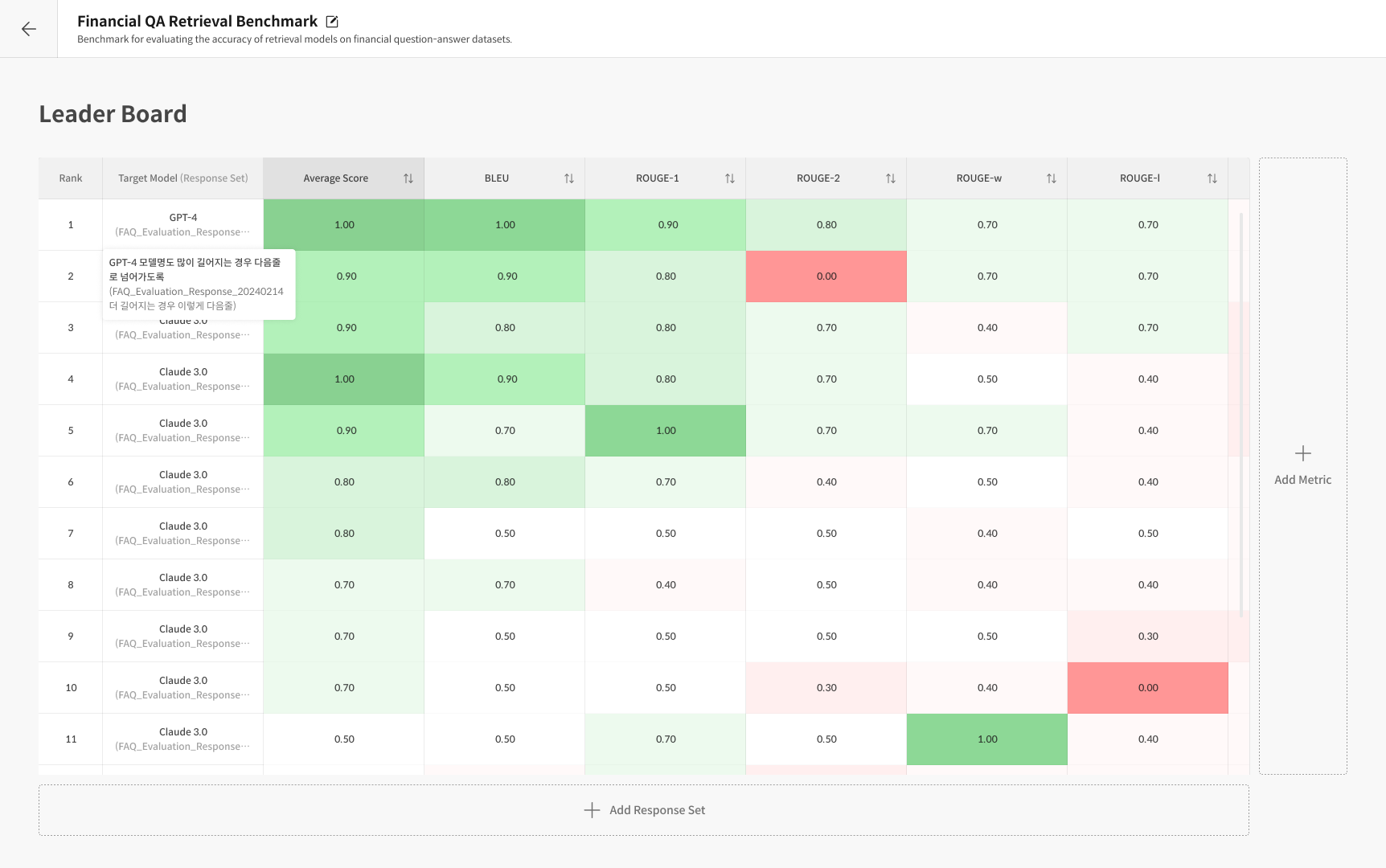
결과를 리더보드 형태로 확인할 수 있습니다.
- BLEU (Bilingual Evaluation Understudy) : n-gram 일치율을 기반으로 문장 유사도를 측정
- TER (Translation Edit Rate) : 참조 문장과 비교해 수정(삽입, 삭제, 교체 등) 비율을 계산 (낮을수록 좋음)
- METEOR (Metric for Evaluation of Translation with Explicit ORdering) : 정밀도·재현율·어순 일치를 종합 평가
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) : 요약이나 응답의 재현율 중심 유사도 평가
- BERTScore : BERT 임베딩 기반 의미적 유사도 평가로, 문맥 수준의 정답 일치도를 측정
Step 1. Task 생성
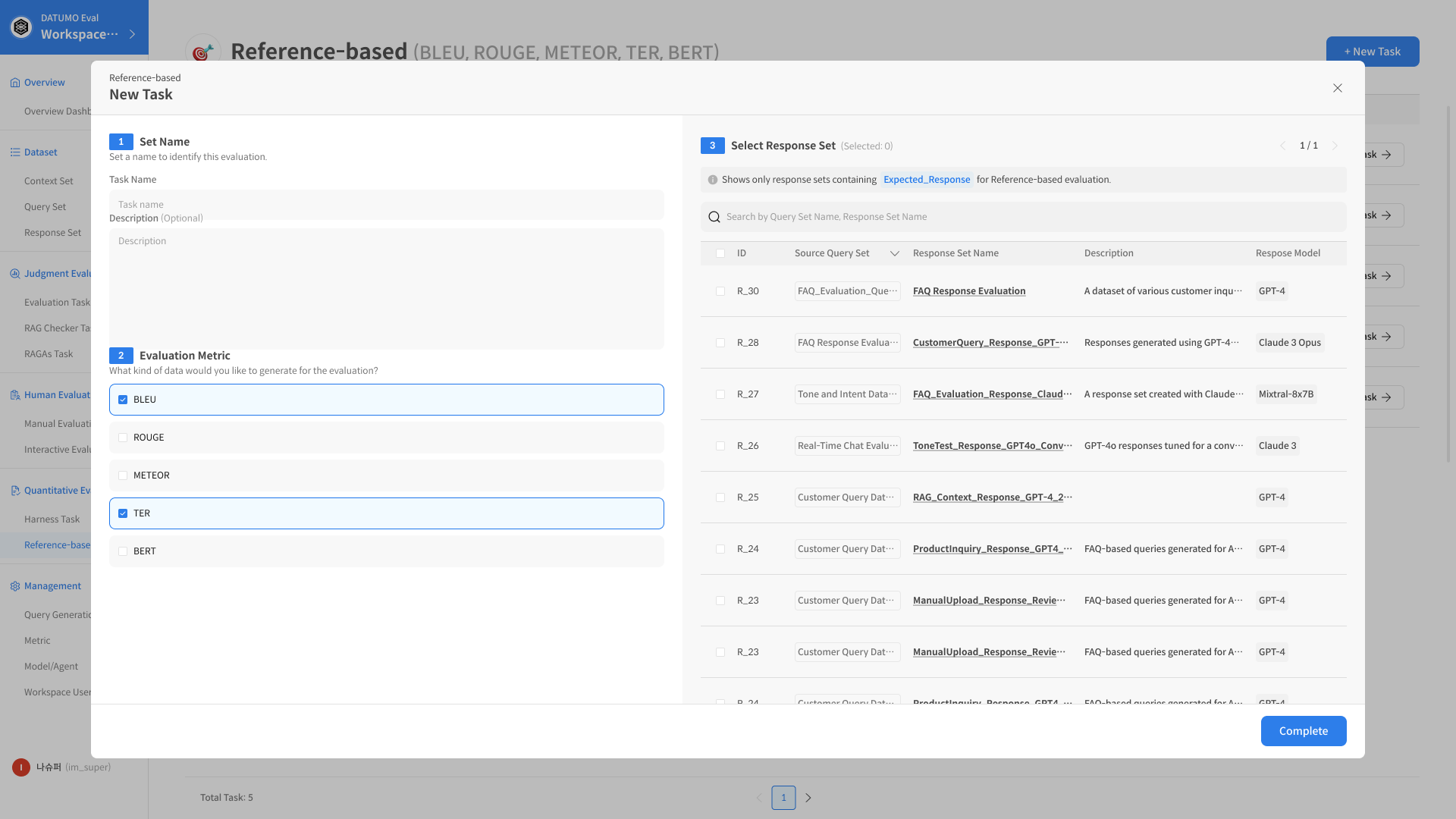
① Reference-based Task 생성
[Reference-based Task] 페이지 우측 상단의 [+ New Task] 버튼을 클릭하여 새로운 평가 작업을 시작합니다.

② Task 정보 입력
Task 이름을 지정하고, Target Model과 사용할 Metric (BLEU / TER / METEOR / ROUGE / BERTScore) 을 선택합니다.
비교 평가에 사용할 Reference 데이터셋 또는 파일을 업로드합니다.
③ RAGAs Task 생성 완료 평가 진행
[Complete] 버튼을 클릭하면 평가가 자동으로 실행됩니다.
결과는 메트릭별 점수와 시각화된 차트 형태로 제공되며,
여러 모델 간 Reference 기반 성능 비교가 가능합니다.