Reference-based
Overview
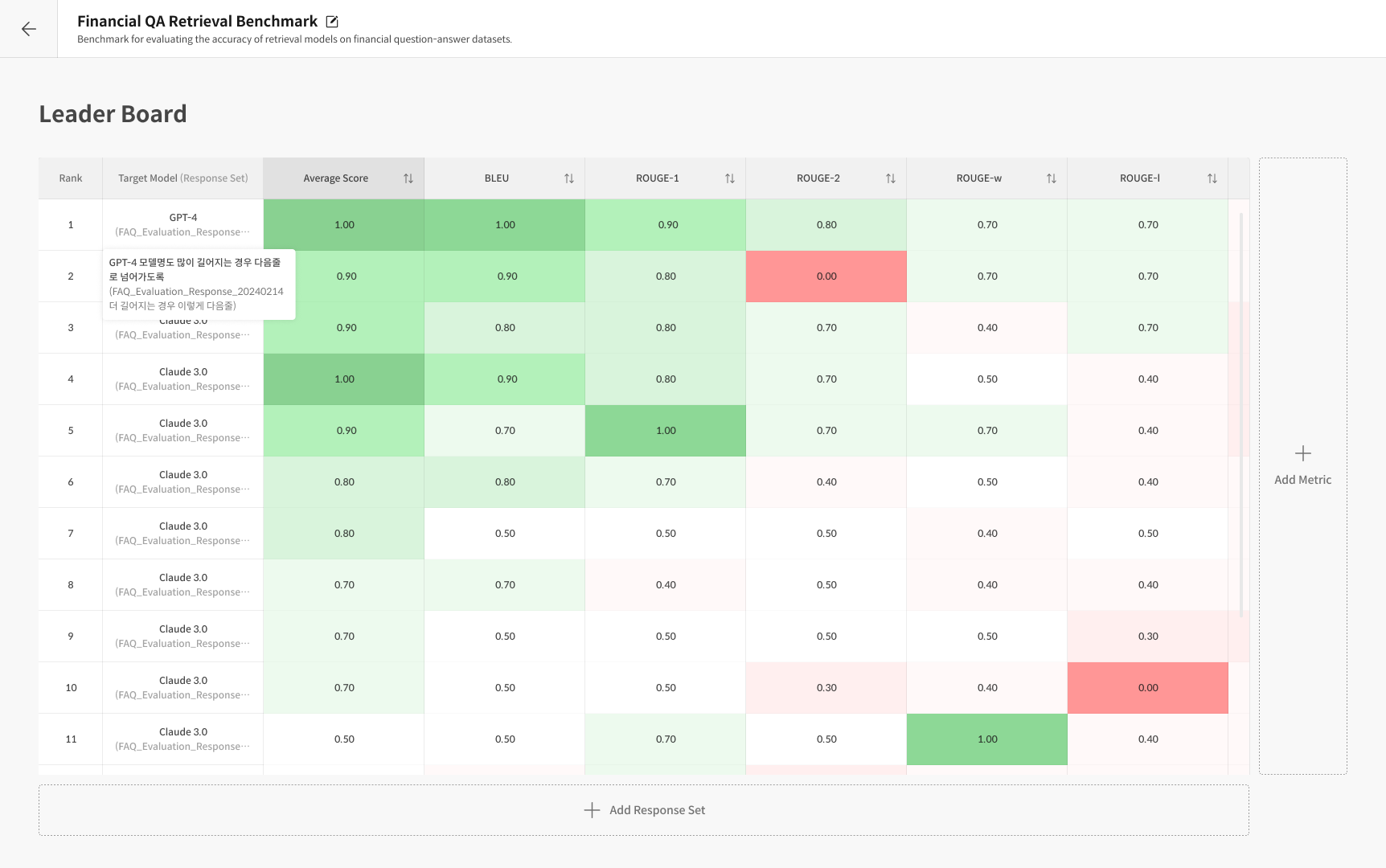
Reference-based Evaluation uses standard NLP metrics—BLEU, TER, METEOR, ROUGE, and BERTScore—to quantify how closely a model’s output matches the reference (ground truth).
Datumo Eval automatically computes these metrics for LLM generations and displays the results in a leaderboard for easy comparison.
- BLEU (Bilingual Evaluation Understudy): Measures sentence similarity via n-gram overlap.
- TER (Translation Edit Rate): Edit rate (insertions, deletions, substitutions) against the reference—lower is better.
- METEOR: Combines precision, recall, and word order alignment.
- ROUGE: Recall-oriented overlap, often used for summaries and long-form responses.
- BERTScore: Semantic similarity using BERT embeddings to capture context-level matches.
Step 1. Create a Task
1) Start a Reference-based Task
On the Reference-based Task page, click + New Task in the top-right corner to begin.

2) Enter Task details
Name the Task, choose the Target Model, and select one or more metrics (BLEU / TER / METEOR / ROUGE / BERTScore).
Upload the reference dataset or file to compare against.
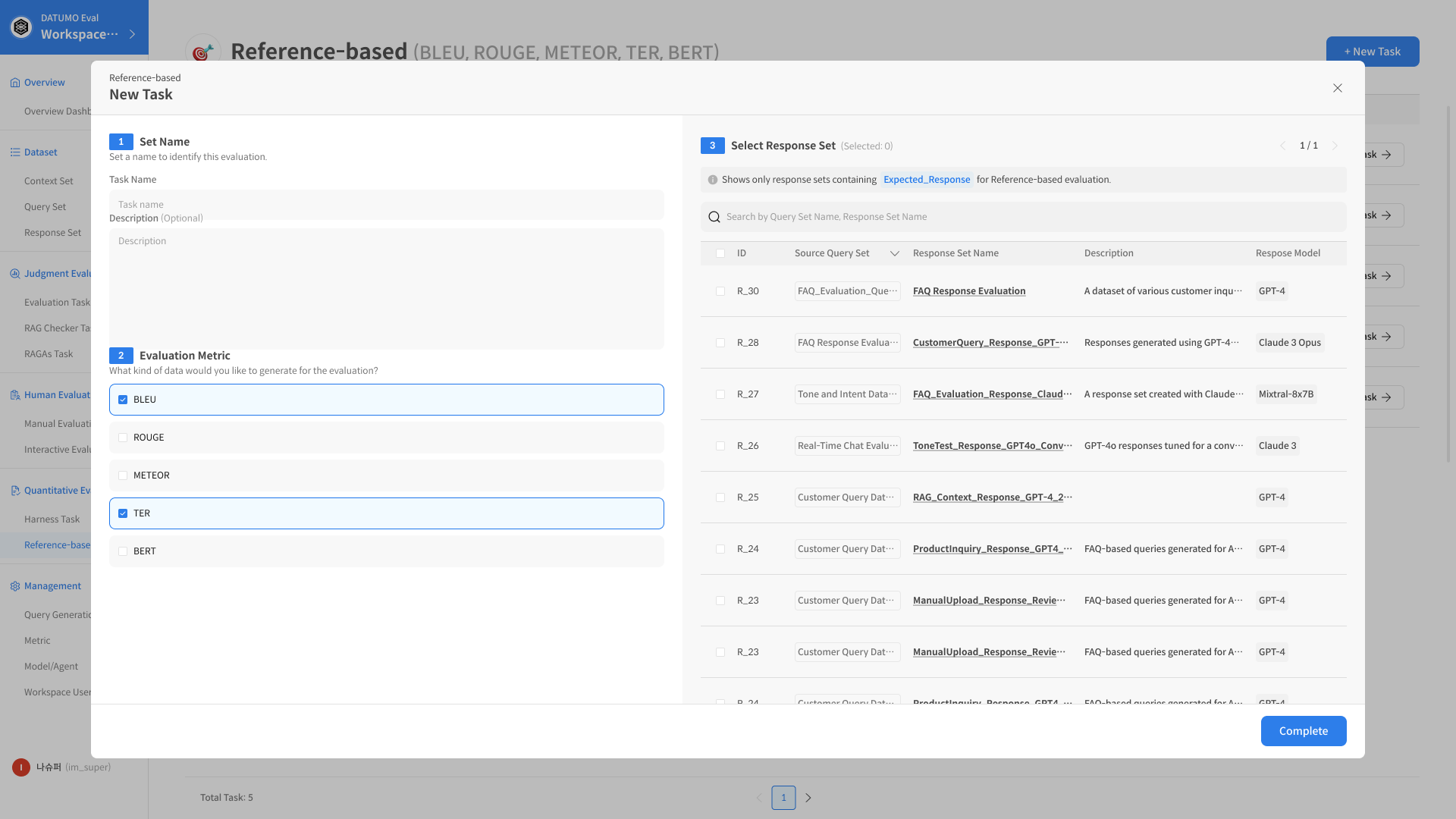
3) Run the evaluation
Click Complete to start the evaluation.
Datumo Eval will generate per-metric scores and visualized charts, and you can compare multiple models side-by-side based on their reference alignment.